
Sommaire
Apache Lucene est une bibliothèque de recherche puissante en Java, utilisée pour créer des applications de recherche performantes telles qu’Elasticsearch et Solr, adaptées à de nombreux cas d’utilisation, notamment dans le commerce électronique. Lucene effectue des recherches ultra-rapides sur de grands volumes de données grâce à ses capacités d’indexation et de recherche optimales. À la fin de cet article, vous aurez maîtrisé les concepts fondamentaux d’Apache Lucene, même si vous êtes novice dans le domaine de l’ingénierie de recherche.
Objectifs d’apprentissage
- Comprendre les concepts fondamentaux d’Apache Lucene.
- Découvrir comment Lucene alimente des applications de recherche comme Elasticsearch et Solr.
- Comprendre comment l’indexation et la recherche fonctionnent dans Lucene.
- Apprendre les différents types de requêtes supportées par Apache Lucene.
- Comprendre comment construire une simple application de recherche utilisant Lucene et Java.
Qu’est-ce qu’Apache Lucene ?
Pour comprendre Lucene en profondeur, nous devons examiner quelques terminologies et concepts clés. Par exemple, considérons les informations suivantes sur trois produits différents de notre collection :
{
"product_id": "1",
"title": "Casque sans fil à réduction de bruit",
"brand": "Bose",
"category": ["Électronique", "Audio", "Casques"],
"price": 300
}
{
"product_id": "2",
"title": "Souris Bluetooth",
"brand": "Jelly Comb",
"category": ["Électronique", "Accessoires ordinateur", "Souris"],
"price": 30
}
{
"product_id": "3",
"title": "Clavier sans fil",
"brand": "iClever",
"category": ["Électronique", "Accessoires ordinateur", "Clavier"],
"price": 40
}
Document
Un document est une unité fondamentale d’indexation et de recherche dans Lucene. Chaque document est identifié par un ID unique. Lucene transforme le contenu brut en documents contenant des champs et des valeurs.
Champ
Un document Lucene contient plusieurs champs, chacun ayant un nom et une valeur, par exemple :
- product_id
- title
- brand
- category
- price
Terme
Un terme est une unité de recherche dans Lucene. Lucene applique plusieurs étapes de prétraitement sur le contenu brut avant de créer des termes, telles que la tokenisation.
Index inversé
La structure de données sous-jacente dans Lucene qui permet des recherches ultra-rapides est l’index inversé. Dans un index inversé, chaque terme est associé aux documents qui le contiennent, ainsi qu’à la position du terme dans ces documents.
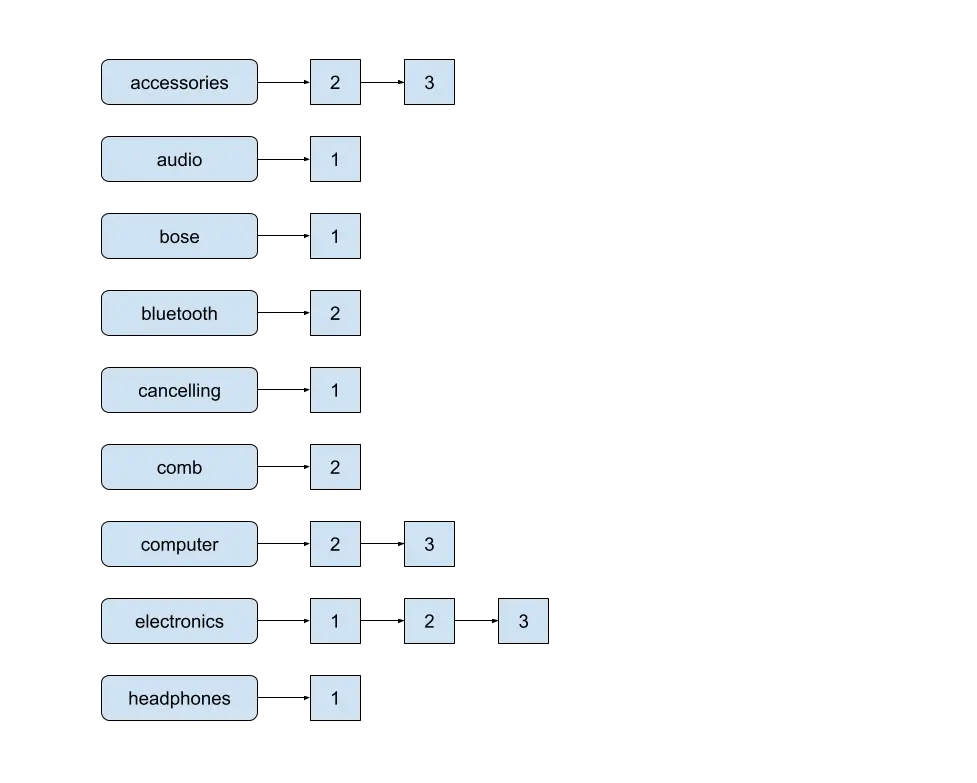
Segment
Un index peut être subdivisé par Lucene en plusieurs segments. Chaque segment est en lui-même un index. Les recherches de segments sont généralement effectuées de manière sérielle.
Scoring
Lucene calcule la pertinence d’un document grâce à des mécanismes de scoring tels que la fréquence des termes inverse document frequency (TF-IDF). D’autres algorithmes de scoring, comme BM25, améliorent également TF-IDF.
Fréquence des termes (TF)
La fréquence des termes est le nombre de fois qu’un terme t apparaît dans un document.
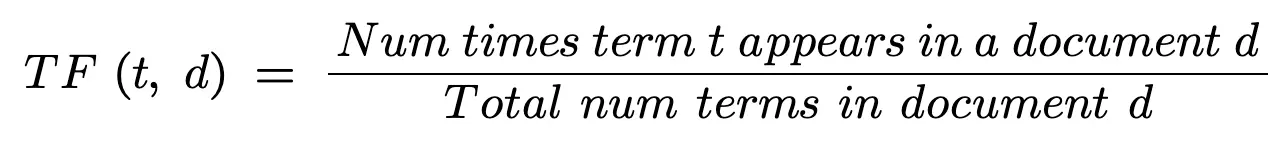
Fréquence des documents (DF)
La fréquence des documents est le nombre de documents contenant un terme t. La fréquence inverse des documents divise le nombre total de documents par le nombre de documents contenant le terme t, mesurant ainsi l’unicité d’un terme particulier.

Fréquence des termes inverse fréquence des documents (TF-IDF)
Le TF-IDF est le produit de la fréquence des termes et de la fréquence inverse des documents, indiquant à quel point un terme est distinctif et unique par rapport à l’ensemble de la collection.
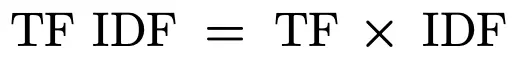
Composants d’une application de recherche Lucene
Lucene contient deux composants majeurs :
- Indexer – Utilise la classe IndexWriter pour l’indexation.
- Searcher – Utilise la classe IndexSearcher pour la recherche.
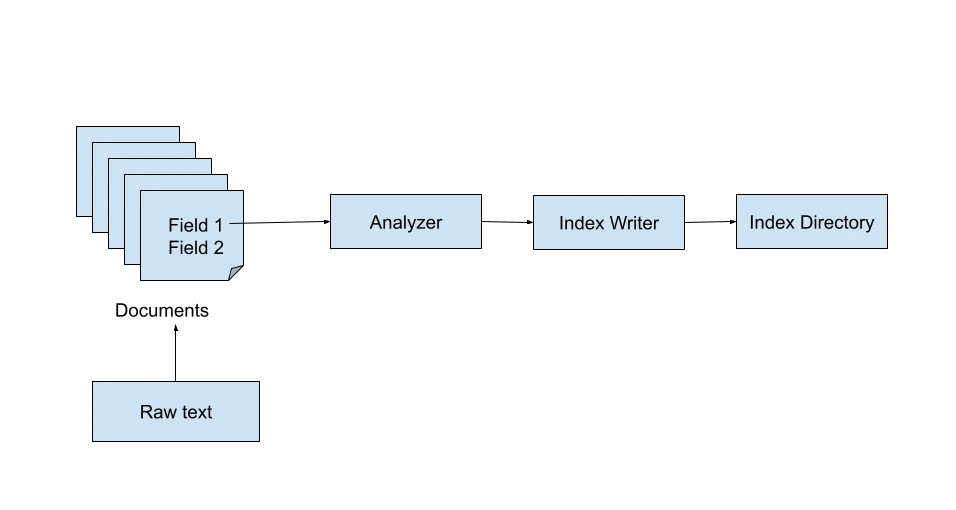
Indexer Lucene
L’index Lucene est responsable de l’indexation des documents pour l’application de recherche. Lucene effectue plusieurs étapes de traitement et d’analyse de texte, comme la tokenisation, avant d’indexer les termes dans un index inversé.
Recherche Lucene
La recherche dans Lucene se fait avec la classe IndexSearcher, qui nécessite la spécification d’un objet Query valide. Une chaîne de requête utilisateur peut être convertie en un objet Query valide à l’aide de la classe QueryParser.
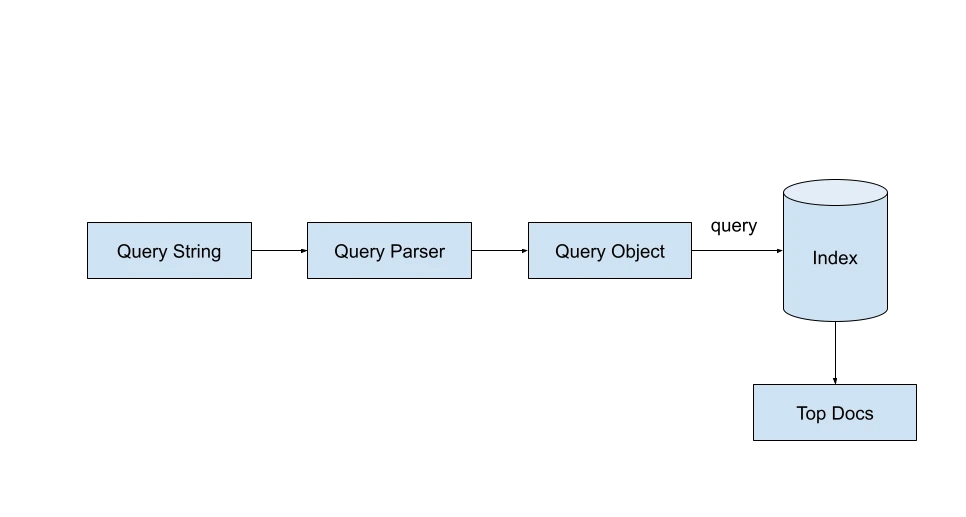
Types de requêtes de recherche supportées par Lucene
Lucene prend en charge plusieurs types de requêtes. Voici les cinq types de requêtes les plus courants :
Requête de terme
Une requête de terme correspond aux documents contenant un terme particulier.
Requête booléenne
Les requêtes booléennes correspondent aux documents qui répondent à une combinaison booléenne d’autres requêtes.
Requête de plage
Les requêtes de plage correspondent aux documents contenant des valeurs de champ dans une plage donnée.
Requête de phrase
Une requête de phrase correspond aux documents contenant une séquence particulière de termes.
Requête fonctionnelle
Calculent des scores pour les documents en fonction d’une fonction de la valeur d’un champ.
Construire une simple application de recherche avec Lucene
Nous avons appris les bases de Lucene, l’indexation, la recherche et les types de requêtes. Maintenant, nous allons assembler ces éléments pour construire une simple application de recherche utilisant les composants principaux de Lucene : l’indexeur et le chercheur.
Dans l’exemple ci-dessous, nous indexons trois documents contenant les champs suivants : Nom et Email. Le nom est ajouté en tant que champ texte et l’e-mail en tant que champ chaîne.
Questions fréquemment posées
Q1. Lucene prend-il en charge Python ?
Oui, Apache Lucene a un projet PyLucene qui prend en charge les applications de recherche Python.
Q2. Quels sont les différents moteurs de recherche open source disponibles ?
Parmi les moteurs de recherche open source, on trouve Solr, Open Search, Meilisearch, Swirl, etc.
Q3. Lucene prend-il en charge la recherche sémantique et vectorielle ?
Oui, il le fait. Cependant, le nombre maximum de dimensions pour les champs vectoriels est limité à 1024, ce qui devrait être augmenté à l’avenir.
Q4. Quels sont les différents algorithmes de scoring de pertinence ?
Parmi eux, on trouve la fréquence des termes inverse fréquence des documents (TF-IDF), BM25, l’analyse sémantique latente (LSA), et les modèles d’espace vectoriel (VSM).
Q5. Quels sont quelques exemples de requêtes complexes prises en charge par Lucene ?
Parmi les exemples, on trouve des requêtes floues, des requêtes de portée, des requêtes multi-phrases et des requêtes d’expressions régulières.